
Benefits of Sync:
- Reduce data-entry and associated errors
- Errors in data will get propagated in sync, but at least they’ll all be the same error 😉
- Access the same data everywhere you need it
- Consolidation for reporting and metrics
- Owning all of your data ( or at least having a recent copy of it )
- Continuity and risk mitgation
- If you have data in a company that disappears, or suffers a data catastrophe you still have a copy of your data
- Single source of truth for data
Security and Data Privacy:
- Our apps are username and password locked ( only System Administrators can use the forgot password feature ) and you should change the default credentials immediately after installation
- Apex developers may be able to invoke sync programatically, but they can’t change any settings
- Data / information / etc. only travels between your Salesforce system and any API that you define
- No data is ever sent to a third party, sfPlugins, except what you might share in support scenario
- APIs must be allowed through Salesforce > Setup > Remote Site Settings before any external endpoint can be called by the app
- If you choose to email logs, logs will be emailed to the source specified
- If you choose to email export delimited data, it will be sent to the email(s) you specify
- When advanced logging and monitoring is released:
- Data and logs may be sent to a supported system ( AWS cloud watch/s3/etc. ) that you configure and specify, data travelling between your Salesforce server directly into the third-party system of your choosing
- For convenience, app authenticated ( logged into an sfPlugins app ) users, it is possible to export all configured Sync Options to excel, and JSON. JSON export can be used to easily copy settings from one server to another ( from sandbox to production, for example )
- Be wary of any confidential, proprietary, or other sensitive information that could be contained in these files and store / protect them as you would PII, sensitive data, or credentials
- When using sfPlugins support, and sharing your sync config – scrub any confidential data out of your config and mock before sending it to us ( please make sure that mock data is still valid – but fake )
Terms:
- Sync – the process of transmitting ( and transforming ) data from a source to a target
- Is composed of one or more sync options ( steps )
- Each step runs in its own process, which its own execution and governor limits
- May be ordered to ensure relational integrity of objects such as with parent-child and x-to-many relationships
- Is composed of one or more sync options ( steps )
- Sync Options – A sync option represents the configuration for one sync ( one Salesforce object for Import, and one API for Export )
- Multiple sync options can act on the same object or API
- A sync option
- Incremental Sync – a sync that contains a subset of records or fields, this should be used whenever possible to ensure speedy, performant sync
- Only the fields and records that have changed in a. time frame or according to criteria / trigger
- Full Sync – sync of all data for a particular resource, object, table, system, etc. includes all relevant data
- But might not include ALL source fields, just mapped fields and resources
- Data Types – represent the types of data that are supported for a given sync. These types map directly to avaialable Salesforce data types
- Types
- Text
- Number
- Checkbox / Boolean
- Object – Array
- etc.
- See documentation for a full list of supported data types
- Files, attachments, and Images are generally not supported at the moment, but links to them are
- Types
- Strong Typing – a system that requires data to be declared as a type ( number / text / etc. ) and enforces that type during an update. That is to say that, you cannot put a number 3.14 into a text field and text “3.14” into a number field. Such a system is called strongly typed.
- Salesforce enforces strong typing
- Javascript (by default) does not
- JSON – Javascript Object Notation is the language of modern APIs
- Reference: https://www.json.org/json-en.html
- Understanding JSON is the key to working with APIs and syncing data between systems
- External ID / Foreign Key – an ID that comes from the originating system
- This is a super important concept for sync
- Used to match a record in Salesforce with a record in an external system
- Used to re-create relationships between foreign objects in Salesforce
- In my external finance system I have two tables, Invoices and Payments. For the sake of argument, I can have multiple payments per invoice. Now, when syncing to Salesforce I have created two new tables, Invoices__c ( with an external id field invoice_id__c ) and Payments__c ( with an external id field payment_id__c ). The objects have a master-detail or one-to-many relationship. When syncing, I would sync Invoices first. Then I would sync payments. Using the external ID with the Upsert flag ensures that new records are created when needed, and existing records get updated. The external id ensures that the data always matches the external system. When syncing Payments, I would want to use the reference ETL transform to get the Salesforce ID of the invoice, and update the reference field with that value to connect the payment to the invoice. * How or if this will work will depend on the nature of your API and data structure on both sides.
- Insert – when syncing, insert new records every sync
- This will not update existing records and could create duplicates ( see upsert )
- Update – when syncing updates records on every sync when a match is found between some ID ( doesn’t have to be a Salesforce ID ) and a value in the API
- Example: In my external system, I track orders by an API field called Order_ID. In Salesforce, I have created an orders__c object and within that object, created a text field called Order_ID__c. That field is set to unique, and an external identifier. When sync runs, we will compare the API field to the Salesforce field
- This will not insert new records and could leave any new records out of the target system ( see upsert )
- Upsert – updates existing records when an ID field ( not necessarily a Salesforce ID – it could be external ) matches, and inserts a new record when no match is found
- This is a super important concept for sync
- In almost all cases, upsert is the way to go for a sync
- ETL – Meaning Extract, Transform, and Loading of data. in this context, specifically the transform feature between API and Salesforce data.
- Examples:
- Convert: An API string to a number field in Salesforce
- Replace: replace one value with another ( useful for pick lists )
- Calc: calculate fields and constants, applying mathematical functions ( such as ABS ) and producing a result
- Examples:
- In-Flight / In-Flight ETL / In-flight Transform – means that data transformation and manipulation happens in real time, between extraction of data from the source system and loading of data into the target system
- Source of Truth – The datastore which is considered the authority or nexus for all organizational data. It is different for every organization and every system, and this term is subjective to the data provider.
- It is the centre of your data universe.
- Push – the system where the data changes sends the data to the system that wants to consume it ( applies to both import and export, depending on your point of view )
- Used for near real-time sync
- Pull – the system that wants to consume the data requests data at regular intervals or when triggered to updated ( applies to both import and export, depending on your point of view )
- Used for periodic sync, reconciliation, and on-demand data ingestion
- Import – Pushing or pulling data into Salesforce
- Export – Pushing or pulling data out of Salesforce
- With the Export app ( click here ), supporting JSON, www-form-encoded, delimited, cdv ( and other formats in the future )
- Mapping / Config / Sync Options – a mapping of Salesforce to API fields including:
- Which API field matches which Salesforce field
- Any transformations that will be applied to the field, and in what order
- Other information such as the type of sync and how to connect to the target API
- Reconciliation – comparing or ensuring that two systems have the same data at a given point in time.
- Example: at midnight, every night, both systems are equal ( for data that syncs )
- Endpoint – a URL that defines a specific API resource ( https://example.com/api/v1/contacts?category=customers )
- Is composed of multiple parts
- HTTPS:// – your domain should always be secure using SSL
- Domain – the base domain you are connecting to ( https://example.com )
- You will need to add this to Setup > Remote Site Settings to be able to call the API from Salesforce
- Resource – the bit that specifies what particular URL you want on the server ( /api/v1/contacts )
- Parameters – any additional query-string (URL) parameters that the API wants passed to it ( ?category=customers ) according to your API documentation
- Is composed of multiple parts
- Method ( API ) – most APIs have endpoints for getting data, posting ( sending ) data, and possibly, deleting data, patching it, or putting it.
- When Importing data – you will probably make a GET request to your target API to return data
- When Exporting data – you will probably make a POST request to your target API to send data
- Load – a term used in this document to indicate the overall effect of processing time, server strain, bandwidth, and associated costs. For example:
- Light / Low load – concurrent sync jobs that finish under 50% of Salesforce execution and API limits, and/or apply little to no strain on the source server, having acceptable cost and performance implications
- Medium Load – concurrent sync jobs that finish under 75% of Salesforce execution and API limits, and/or apply little to moderate strain on the source server, having tolerable cost and performance implications
- High / Critical Load – concurrent sync jobs that finish above 75% of Salesforce execution and API limits (or exceed them at any frequency ), and/or apply moderate to severe strain on the source server, having intolerable cost and performance implications
- Request – when calling an API you make a request, this is true if want to GET data from the server, or POST ( put / push ) data to the server ( See: API Methods )
- when using your browser and visiting sfplugins.com the browser is making a GET request
- when submitting our contact form, the browser sends the form data through a POST
Sample request ( cURL ):
curl https://login.salesforce.com/services/oauth2/token \
-d "grant_type=password" \
-d 'client_id=your-client-id' \
-d 'client_secret=your-secret' \
-d 'username=user@domain.com' \
-d 'password=passw0rd' \
-H 'Content-Type: application/x-www-form-urlencoded' \
-H 'Accept: application/json'
The method of this request is POST because we are sending data to the server ( the lines that start with -d for data )
The data is commonly referred to as the "payload" or "body"
A GET request has no payload ( body )
The -H implies a header, which in this case tells the server that we are sending form-encoded data through curl, but we are accepting JSON back.
The API creator determines which headers, content-types and response-types ( accept ) are supported.
The request payload / data is used for:
Import: not usually used, as a GET request is more common than a POST/PUT/PATCH
Export: this is the data loaded from Salesforce, transformed, and made ready for the target server to use as the API is dinged to do ( like copying a record from on SF org to another )- Response – this is the response that a web server sends back as a result of a request
- Includes a status code ( 200/201, 404, 500, etc. )
- Probably includes headers, like Content-Type:application/json
- And ideally, has a body
- The body is additional text ( usually json ) included with the response
Sample response from curl:
< HTTP/1.1 200 OK
< Content-Type: application/json;charset=UTF-8
<
{
"access_token" : "sometoken",
"instance_url" : "https://domain.salesforce.com",
"id" : "https://login.salesforce.com/id/someid",
"token_type" : "Bearer",
"issued_at" : "123456789",
"signature" : ""
}
Here, the status is 200 OK which is a great response. A 404 not found would mean that we used the wrong URL ( it doesn't exist ). A 401 unauthorized would mean that we didn't send the right authorization headers or payload and we don't have access to the resource. And a 500 means we really messed up, the server messed up, or that the API programmers were lazy and made every error a 500. But any way you slice it, a 500 is some kind of error processing the request. Ideally, a 500 response comes with a body that explains why the error occurred ( that's what we do ).
There are other codes, but we don't need to cover them here.
The response also includes a header, Content-Type, that tells us the format of the response body.
In this case, the body is the returned JSON:
{
"access_token" : "sometoken",
"instance_url" : "https://domain.salesforce.com",
"id" : "https://login.salesforce.com/id/someid",
"token_type" : "Bearer",
"issued_at" : "123456789",
"signature" : ""
}
The body is the part that gets mapped in an API Import, transformed, and loaded into Salesforce.
- Payload – refers to the data ( text ) that an API sends in the body of a request ( the body is just a placeholder for the text/data and is empty by default )
- If this was an email message instead of an API call, the payload would be the message
- Payloads are commonly formatted as JSON, x-www-form-urlencoded, XML, etc.
- Header – like the to, cc, and subject lines of an email message headers convey important information to the desired API server
- Content-Type : what type of content we are sending ( json, text, xml, form encoded, etc. )
- Accept: what type of content we hope to get back ( if the API server supports it )
- Authorization: a token ( bit of text ) that proves we have access to the server ( are logged in ) and to the resource we are requesting
- Tokens are usually returned in response to an authentication request, and in the case of named credentials, all this is handled for you by Salesforce
- Query-string – the URL ( see: Endpoint )
Sync Types:
So, you want to sync data from one system to another…
From our point of view, the goal is to either:
- Import Data into Salesforce
- Export Data out of Salesforce
Therefore, the concepts of Push, Pull, or Hybrid Sync, is relative to the target or the source, but the advantages of each sync type are the same for both Import and Export ( supposing there are always exceptions to every rule )
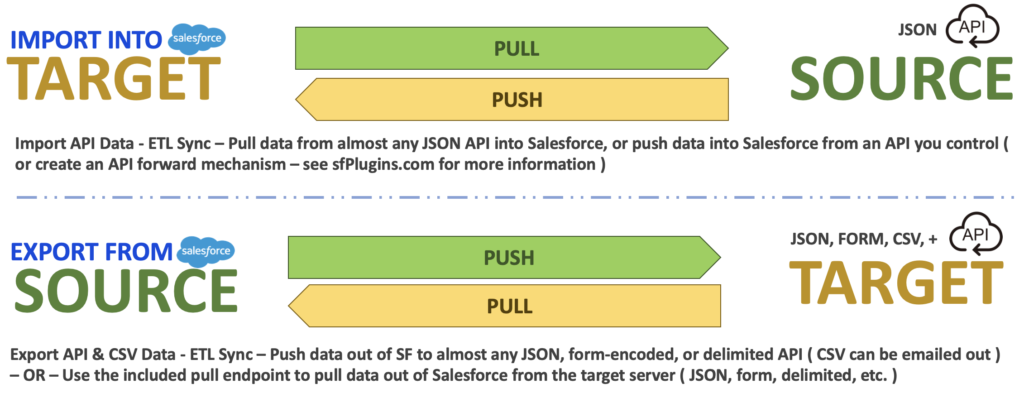
Push Sync
This is the gold standard for types of sync.
Push Sync refers to a source system that sends data to a target system ( rather than the target system requesting data from the source )
It might seem like a small difference, but in practice, the system in which a change occurs is the best candidate to perform a push sync.
This is because the pusher knows what changed and how many things changed, while the puller has no idea. Therefore, the puller has a few options: to request a specific thing, all things, or a subset of things ( usually within a time period to avoid syncing everything all the time )
While maybe not true in all cases, the puller has no idea what changed on the system that initiated the chAnge and therefore may pull data that is not needed, and that impact will have a cost in terms of: bandwidth, api limited, licensing costs (if any) perforce of both systems, etc.
So push is preferable. The pushing system knows what’s changed and can choose to: send the update(s) in real time, or for performance and cost reasons, bundle changes into smaller sets ( last minute, hour, day, etc. ) depending on how fresh the data needs to be ( it usually doesn’t actually need to be real-time )
So, a push sync is usually called in real-time or in manageable time increments depending on the speed required ( see: Scheduling Sync for more information )
Advantages:
- Send only the data ( records ) that have changed ( no guessing )
- Usually faster ( near-instant to practical time increments )
- Therefore better performance, cost and impact on both systems
Disadvantages:
- Might not always be possible “out of the box” as you will usually need one of: the ability for the originating system to push to an endpoint (URL) you specify, a server you control, and the ability to push data via API, some services like Zapier ( for example ) may provide low or no-code methods for doing the same as well.
- See: API Forwarding for more information
Pull Sync
The third-best type of sync.
Pull Sync refers to a source system that requests data from a source system ( rather than the source system pushing data to the target )
It might seem like a small difference, but in practice, the system in which a change occurs is the best candidate to perform a push sync. And when that is not possible, you pull.
* Caveat: pull does have it’s uses and advantages – among them, nightly cleanup & error correction ( See: Reconciliation & Error Correction )
Advantages:
- When you can’t push you pull.
- Good for low impact situations
- Example: I don’t need information in real time, but I want the record to be updated with outside data whenever I finish editing it. In that case I can use after update and insert triggers to update the record after I’m done with my edit.
- If I wanted the record to be updated before I opened it, I could have done an overnight sync, or if needed more frequently, say every hour.
- Example: I don’t need information in real time, but I want the record to be updated with outside data whenever I finish editing it. In that case I can use after update and insert triggers to update the record after I’m done with my edit.
Disadvantages:
- Don’t know which records have actually changed on the originating system
- Not a big deal for overnight data, because you’re probably going to request all new data in the last 48 hours
- Why are we requesting two days of data for an overnight sync?
- Just in case we missed something yesterday. This could easily be 25 hours, or 30, but it’s good to build in a little redundancy to make sure that both systems are always reconciled.
- Why are we requesting two days of data for an overnight sync?
- Therefore, we have to request all records that have changed since the last sync. In many cases, volume will be low, so it might be good practice to request all data changed in the last two or more time-periods, to ensure that nothing got missed ( for any reason )
- Not a big deal for overnight data, because you’re probably going to request all new data in the last 48 hours
Hybrid Sync:
Is a mix of push and pull ( and may also be a combination of import and export ). In any event, there may be situations where you feel pushing data every 5 minutes to Salesforce will give near real-time updates for most objects. But pulling numbers from a finance system, or market data ( which is updated overnight ) needs to be pulled because the originating system does not support push, and you can pull in new data at regular intervals.
Environment, Preparation, and Planning
Having a plan for your sync ahead of time will yield the best results:
- Choose a data source for Import or Export ( Salesforce, API, HR or Finance System, etc.)
- Confirm that both the target and source systems support API sync ( Salesforce does )
- Define your use-case
- We need to update the financials every night so that Sales and the Leadership Team can see the latest numbers in the reports
- Identify the data-sources that you want to sync
- For the example case above, you might need:
- Market data from a third-party API / website
- Finance data from you Finance System’s API
- Data from your Sales Salesforce Cloud
- For the example case above, you might need:
- For each data-source – Identify object / table / entity ( clients, accounts, contacts, sales numbers etc. )
- And the API documentation for those entities
- For each API resource / endpoint make a list of
- field name ( from api not the database ) – data type ( number, boolean, text, etc. ) – length/size of field
- for pick-lists and drop-downs, provide the values ( these may need to be transformed with the Replace ETL function between systems – capitalization and specific spelling matter in Salesforce )
- field name ( from api not the database ) – data type ( number, boolean, text, etc. ) – length/size of field
- Determine the direction for sync
- Export data from Salesforce ( even to another sf org )
- Import data into Salesforce ( even from another sf org ) ( click here )
- Install and configure the app according to the quick-start guide under App Docs
- Determine the desired frequency for sync
- Instant ( near real-time, ~15 seconds to 1 minute at the fastest )
- Possible for small data sets and single records ( ideally via push )
- Actual sync time is determined by Salesforce Apex Batch Job execution and queues
- Repeated Sync time shorter than 5-10 minutes for large numbers of records is not recommended
- https://developer.salesforce.com/docs/atlas.en-us.apexcode.meta/apexcode/apex_gov_limits.htm
- Hourly, Nightly, etc.
- Instant ( near real-time, ~15 seconds to 1 minute at the fastest )
- Determine the actual frequency for sync
- Practically speaking you need to respect the Salesforce limits for API calls, Apex execution time, Number of queued batches etc.
- For high volume applications real-time sync is not practical
- The source system may also have costs associated with: the number of API calls, the max calls allowed per day/hour/etc., bandwidth cost, database locking ( but we hope not ), etc.
- The average time it takes for a sync to complete * a number that leave room for unexpected delays, etc.
Day Zero – Reconciliation and Equalization
( See: Backup and Sandboxes before trying any sync in a production environment )
* This only applies to existing data in the target system which may be liable to be over-written.
Make sure that your source system has the latest, freshest data, and that no mapped sync fields on the target system have better data than the source – in which case you will need to update the source system before syncing to the target.
Fields that are not mapped in sync will not be affected by sync.
This is likely not needed if you are syncing into a fresh or empty system, or objects/fields that were empty or non-existant before sync.
Before syncing two systems, keep in mind that sync can be a ruthless process if you haven’t considered the implications.
Example : Syncing contacts from one Salesforce Org to another, using email address as the Upsert ID
- In practice this sync will:
- Take contacts from the source org and:
- update contacts in the target org where emails match
- Be wary of allowing duplicate emails in this case or use a different external ID
- insert contacts into the target org where email matches are not found
- update contacts in the target org where emails match
- Take contacts from the source org and:
- This is exactly what we want, and if the target org has no contacts, or empty contacts, there’s no problem
The potential problem arises when the target org has existing data ( fields ) that are set to be overwritten by the source org.
- Always backup your data and test in sandbox before altering production data
- Always compare ( reconcile ) the target data against the source data before performing any sync operation
- Make sure that the source system has the sum of data from target + source
- If the target org already has information in a field ( say address ) and the source org has bad/incomplete/missing/empty data for the mapped field – the “good data” will almost certainly get overwritten on sync
- While sync allows you to skip null values, this method should not be relied on for data integrity.
Performance & Quality Considerations
When determining your sync strategy, you need to think about the performance and impact of sync against your desired goals. And you also need to think about how to ensure completeness / quality of your sync ( See reconciliation and error correction )
- Generally speaking you want to sync the smaller amount of data possible per sync, taking load into account
- Batch / bundle / segment data into chunks that balance the number of syncs per hour
- A sync should send the smallest amount of data per time period possible
- Usually this is achieved by querying with time offsets ( records changed in last 5/15/30/60 min, nightly etc.)
- Not applicable to single record, on-demand, triggered, sync
- Triggered sync should not be used where the number of transactions exceed available Saleforce and external system limits
- You will need to test your sync in as close real life situation as possible ( see: Testing and QA + Error Correction and Reconciliation )
- When calling APIs and using paging ( next tokens ) you could end up getting as many as 100 API calls per batch, each call will take time to return, counting against Apex script execution limits of 60 seconds ( for import )
- Avoid returning more than 5mb of data ( for import ) per sync option
- Where possible, limit API data to the fields necessary to avoid unnecessary parsing of data by the sync engine
- Every ETL operation will add some small overhead or processing time to a record, when dealing with thousands of records
Syncs that exceed execution limits may not appear to finish – in which case go to Settings > Apex Jobs and examine the Status email for the failed sync.
Sync Mapping
A Sync Mapping represents the rules for copying and transforming data between the source and the target.
All sync mappings ( and some/all config options ) are configured using JSON. It may seem daunting if you are unfamiliar with it, but it make a lot of sense the more you use it.
Our apps come with a mapping “helper” that attempts to guide you through the creation of sync mappings ( and for Export config as well )
One mapping is equivalent to one step in a sync process ( the entire sync could be 1 step ).
One Sync Mapping:
source field > transform > destination field
* Pro tip: if you are new to sync, try the most simple mapping possible to start. Only required fields ( say Name for example ) and no complex ETL transforms ( some data must be converted through ETL for data-typing reasons )
For example:
{
"name-last": "LastName"
}When preparing for your sync, you idenitifed the fields you wanted to update from the target.
You also took note of field data types ( integer, decimal, string, etc. ), field lengths, and any other rules.
Now, looking at your target system, identify the API or Salesforce fields you need to sync to.
Salesforce is strongly typed – meaning that you can’t just take an API text field with a number in it “9” and insert/update that into a Salesforce field of type integer ( in basic javascript, this would work ). ( applies to Importing data )
Similarly, with JSON ( the language of modern APIs ) you can only pass: text, numbers, booleans ( true/false ), nulls, objects, or arrays – which means that in some cases, Salesforce field may need to be transformed to the format your API expects ( applies to Exporting data )
Beyond that, Salesforce enforces pick list values, and your API may do the same. Take the Salutation field for example:
- If the API returns Mrs and Salesforce is expecting Mrs. – you will encounter a Salesforce error on import
- On export, the reverse is likely true as well
To mitigate this issue, we will need to apply an ETL Transformation and change the type ( or cast ) by converting text to numbers ( or vice versa ), or by replacing a value like Mrs with Mrs.
There are other transformations as well, calculations, validations ( for Import ) and actions that are possible when importing or exporting data.
In the case of data export, the data may also need to be escaped or encoded. ( see Export in-app documentation )
ETL Transforms
ETL – stands for Extract, Transform, and Load – which simply put, can be thought of pulling data from the source system, transforming that data in-flight ( in real time, as needed, if needed, on a field by field basis ) and loading that data into the target system.
We can assume that the extraction and loading are table stakes for any data sync, while transformation is optional.
Therefore, when discussing ETL, we are really taking about the T.
Transformation is a valuable and sometimes necessary feature for any sync process. Systems may be particular about the data types they ingest ( load ) the format of that data ( case, wording, etc. ), or require data to be split, joined, or otherwise manipulated before insertion into the target system.
* See in-app documentation for a full list of transforms and features offered for Import and Export
Common transforms ( included in our apps )
- Convert / Cast / Re-type data
- Split fields ( Import )
- Join fields
- Calculation
- Replace
- Modify ( uppercase, lowercase, title case, etc. )
- Escape ( Export )
- Encode ( Export )
- etc.
API Integration
Before connecting to another system ( for import or Export ) please ensure that you are familiar with the APIs to be used and their documentation.
Import: Only JSON is supported
Export: JSON, x-www-form-urlencoded, delimited / csv, ( future updates may include xml, flat and other formats )
Test your API with cURL, Postman, or any other tool before attempting to connect to it in Salesforce.
* The safest and best way to authenticate to APIs via Salesforce is to use a combination of: auth providers, external credentials, and named credentials
* Before calling any API from Salesforce ( Import / Export ) add the endpoint ( URL ) to Remote Site Settings
For Salesforce, you can get an auth token through curl:
curl https://login.salesforce.com/services/oauth2/token \
-d "grant_type=password" \
-d 'client_id=your-client-id' \
-d 'client_secret=your-secret' \
-d 'username=user@domain.com' \
-d 'password=passw0rd' \
-H "X-PrettyPrint: 1"* For most APIs you will need to authenticate to the API in order to push or pull data for security reasons
Tokens are usually returned in response to an authentication request, and in the case of named credentials, all this is handled for you by Salesforce. In the case of custom auth, you specify the auth server, method, and payload, and we grab the token and use it for subsequent requests
That token is then used to call the desired API ( such as GET /contact ) which will return a response. Example below:
{
"FirstName": "Joe",
"LastName": "Tester",
"AccountId": "001D000000IqhSLIAZ"
}For Import – make sure that the API response has valid data and contains all of the fields that you need.
- In a perfect world, your API returns only the fields that you need ( this is for performance reasons )
For Export – make sure that you can POST ( or put/patch/delete ) data properly, according to the API specification, and that you get the response that you expect. Usually this is a 200/201 type status and some meaningful message indicating success, and any other messages that you expect.
If everything works in cURL / postman / whatever you use, then you’re ready to set up an auth provider, named credentials, and/or external credentials in Salesforce.
If you don’t know how to do that, and can’t figure it out, you can always use our support option from the contact page – bearing in mind that support above the included two hours per license is a paid service. It should typically take under an hour to set up if you have valid credentials, but named/external credentials in Salesforce can sometimes be finicky as well ( we feel your pain ).
There is also an option to use custom auth ( for debugging purposes ) and have the sync engine get the auth token for you, but should be used with caution, as an excel or json export of your config settings, can reveal privileged information and should be handled with care.
A working, valid API and a valid, correct sample response ( for Import sync Mock ) is all you need to start mapping.
API Forwarding When Have your Own Web Server or When Your Source API Doesn’t Support Push ( for Import )
If you have your own system / API / web server and database, and are handy, you can push data directly into the Import app ( or pull from the export app ) using the included endpoints ( API URLs ) that come with the Import and Export apps. How to do that is included in the in-app documentation for each app, and should be relative straightforward for anyone who has ever built an API.
On the other hand…
Let’s say you want to PUSH data from www.best-hr-system-no-really.com into your Salesforce org. Which you would want to do, because it’s efficient, and you should always push when you can.
But…
If your source system doesn’t support push, but you want to push anyway ( because you know when data changes on the source system ) you can use a server you control to:
- retrieve an API response from the source
- wrap that response with a few extra lines of JSON
- send the new payload to the Import sync endpoint
Data Protection – Source of Truth and the Target System
* Important: See: Day Zero – Reconciliation and Equalization
* Feature update: differential sync is planned for 2024 release ( environment diff + reconciliation + rule engine )
There are many goals and use-cases for sync, but the most common are reducing data-entry and re-entry, and having a single source of truth.
In any case, typical goals include ensuring that your data is:
- Current
- Correct
It is critical that before you sync data, that you make sure that the source system has the sum of the most-correct source and target data ( for mapped fields )
Unmapped fields are unaffected by sync between systems.
This ensures that you do not accidentally overwrite a richer data source, with an emptier or less rich data source.
You should always make sure that the data being updated on the target system is read-only before implementing sync.
- Prevent accidental overwriting good data with bad
After sync is initiated data should only be entered on the source system ( see point above ).
- Otherwise the data entered into a mapped target system field would get overwritten by the source on sync.
The source of truth does not need to be the origin of all data
- Sources of truth subjective to the person / organization. It is the centre of your data universe.
- Your HR provider will consider their database there source of truth
- Your finance provider will consider their database the source of truth
- Your source of truth is the sum of all your data
- Your databases, warehouses, and applications
- The portions of third party data you want to import
- Any other external data that you want to ingest ( import ) to understand
Back up your data as frequently as possible and retain it for a period that makes sense.
- Your best protection from disaster will be to have regular full and incremental backups of your data
- Retain as many of those backups as practical, for as long as you can
- regulations may specify a specific retention period for records and data ( 5 or 7 years, etc. )
Sync Execution – Ordering and Relational Sync & Ensuring Data Completeness
Sync is generally reliable, dependable, safe, secure, and low risk.
But what happens when it isn’t?
The order of sync can be important for related objects / tables / resources. Most databases have both hierarchical relationships between objects, and sibling relationships. To minimize the number of sync operations and the currency of data, it can be important to invoke sync in the right order.
- Sync contacts before accounts in order to link the contact to the account
- Sync invoices before payments
- etc.
There are number of ways to sync data through our apps:
- Sync all active sync options
- Sync by object ( Import only )
- Sync by options ID
All types of sync can be invoked through Apex / triggers
All types of sync can be scheduled
When syncing ALL, execution order cant be guaranteed.
- Salesforce Apex Batch jobs execute on their own schedule, ideally at the time requested, but this is not guaranteed
The only way to guarantee execution order, is to:
- Plan the order or execution
- Know when one sync has completed
- Not straightforward, but can be guesstimated in terms of time.
- Initate the next sync in line
- repeat
Ultimately, if I need to sync 5 objects, every 5 minutes, I can sync object 1 in minute 1, object 2 in minute 2, etc. so that sync repeats at the dished frequency but there is time enough between syncs.
If this doesn’t sound like the perfect method, you’d be right. In a perfect world, we would have a complex program that was able to track syncs, data discrepancies, changes, etc. but that’s only possible on a one-off custom code basis and would be prohibitively expensive for many organizations.
Therefore, we trade some control and precision for flexibility, cost, and time to get sync running ( days vs months ).
So,how do you ensure that all data has been synced?
- Sync only the data and a fields you need at a reasonable frequency
- This is knows as incremental sync and syncs only changed records within a timeframe / criteria / trigger
- For relational objects and resources, you might need more time between syncs to help ensure they occur
- Consider nightly larger syncs that cover the last day ( or days ) to ensure that any failed / missed / out of order syncs get resolved
- Do this prior to any reconciliation and potential error correction
- Create, run, and monitor frequent ( daily? ) Reconciliation reports ( See: Error correction & reconciliation for more info )
- Compare system 1 with system 2 and determine if remediation is necessary
- sfPlugins may release such a system in 2024
- Compare system 1 with system 2 and determine if remediation is necessary
Sync Scheduling and Triggering
There are number of ways to sync data through our apps:
- Sync all active sync options
- Sync by object ( Import only )
- Sync by options ID
All types of sync can be invoked through Apex / triggers
All types of sync can be scheduled
For the Import App you can also push data to Salesforce. For the Export App you can also pull data from Salesforce.
In practice when, where, and how to trigger your sync will depend on your sync strategy as defined above, using the tips, guidelines, and strategies outlined.
Backup and Sandboxes
Always back up your data and test sync in a sandbox, dev, or test environment until you are sure that sync works the way you intend.
Sync is generally safe, stable, secure, and reliable ( assuming that you are syncing within limits )
However, human error when changing/modifying/setting up sync can lead to either:
- Nothing happening ( the best case )
- Overwriting something you didn’t intend to
In practice, if you have followed this guide and the documentation, the risk should be manageable, but in the data world in general, follow this advice:
Trust but verify.
Set up sync in sandbox or dev environment. Back up your data regularly and test your recovery procedures.
Test until your are sure sync works the way you intended it to work.
Read the section on Error Correction and Reconciliation – you want to check and/or automate a process that compares your source and target data on a periodic basis ( even if it’s a spot check ) to make sure that sync is continuing to work as intended.
In general, all of the friction in sync is in the setup, and once running can be left for months or years without modification.
Testing and QA
We don’t have a lot to say on this subject at the moment, as its out of scope for this product, but we will say that you should test thoroughly before deploying sun and in the days and weeks after.
Monitor sync on a regular basis.
Read the following section on reconciliation and error correction.
Diff(errential), Reconciliation and Error Correction
* Feature update: differential sync is planned for 2024 release ( environment diff + reconciliation + rule engine )
A sync can fail for any number of reasons, but the most common are probably:
- API failure
- Timeout / Outage / Etc.
- Changes to API ( endpoint, response body, fields, headers, authentication, etc. )
- System failure
- System limits exceeded ( such as Apex script execution – make your sync steps smaller )
- Outage, distaster, etc.
- User Error
- Configuring sync incorrectly
- Running sync faster than previous syncs or dependencies can finish
- Exceeding target or source system limits ( API limits, bandwidth, licensing, transaction size, etc. )
- Etc. users are exceedingly adept at creating error conditions
One of the best ways to ensure data integrity is to:
- Monitor sync for failures
- See logging and monitoring
- React to failures individually, or provide “fail safe options”
- Incremental sync every x hours + nightly sync of last 25-48 hours
- Create a differential “report” ( this could be a programmatic comparison with no user interface or display )
- Compares all mapped source and target fields
- Source_field_A == Target_Field_A ( and so on )
- Compares all mapped source and target fields
- Define exceptions ( let’s say that a small sync runs every 15 min )
- In the exact moment sync completes, both systems should be equal
- A user / process / etc. could change the data between syncs and we would expect the source and target to be “whole” at the next sync
- Due to the nature of Salesforce ( and the majority of other systems ) instantaneous sync is not practical, especially at high loads
- Systems that are updated very frequently will result in more “diffs” (differences) per “report”
- Therefore, we should generally define exceptions as data that is not “in sync” ( equal ) within a defined timeframe determined by
- How frequently data usually gets updated
- In many systems less than once a day on average, and in very high volume systems, with very frequent changes, it will not always be possible to do a proper diff without being able to see the transactional history of the source field.
- Were the fields equal between source and target at the time of sync?
- In many systems less than once a day on average, and in very high volume systems, with very frequent changes, it will not always be possible to do a proper diff without being able to see the transactional history of the source field.
- Expectations of currency vs. performance vs. practicality
- Practicality determined by limits of target + source system + padding time
- Padding time equal to the longest time a sync can be expected to finish after being invoked + certainty that the last sync succeeded
- How frequently data usually gets updated
- Handle exceptions
- Decide what to do when fields are not equal
- Should they always be equal?
- At the moment of the last sync, yes.
- But we cannot know if data has changed between syncs.
- We plan on implementing a visual differential report and system to address exceptions
- Should they always be equal?
- Whether you have a visual report or not, is not as important as you might suspect, what you actually need to do is:
- Catch exceptions and be able to do something with them, individually, or in bulk
- Decide what to do when fields are not equal
- Differential & Error Correction
- The term correction is used loosely here, as not all sync discrepancies have a material effect if they are not “corrected” within an arbitrary time frame
- The key is that you react to exceptions
- According to your business rules, time expectations, the capabilities of all systems, including the sync engine, and reality / practicality
- The actions that you might take are entirely driven by your needs
- Usually you solve sync failures by retrying the sync ( or fixing the configuration, if that is the source of the error )
Logging and Monitoring
( See product roadmap for upcoming changes to logging and monitoring )
The Import and Export apps come with limited ( last 10 logs are retained ) logging ability out of the box and have the ability to forward logs via email
( Import mainly ) Syncs that exceed execution limits may not appear to finish – in which case go to Settings > Apex Jobs and examine the Status email for the failed sync – it is not possible to update the final log status after execution times have been exceeded.
Causes: typically execution time
- Calling many API pages in one sync option ( max 100 ) may eat up a considerable chunk of Salesforce’s allowed execution time
- Thousands of records with complex ETL may eat up execution time
- Overall load on Salesforce side may eat up execution time
- Data sets that exceed salesforce limits ( typically above 5mb per execution of a single sync option )
Mitigation: try syncing fewer records or pages, or break sync up into multiple steps, until sync succeeds without observable failure
Troubleshooting and Tips
Export API & CSV Data – ETL, Sync, and Scheduler
Data Export Release Notes and Roadmap 2023/2024
Import API Data – ETL, Sync, and Scheduler
Data Import Release Notes and Roadmap 2023/24